Responsible AI to Accelerate Research Funding
How Stanford Impact Labs Is Learning to Use AI in Grantmaking Decisions

Every year, governments, foundations and other funders allocate billions of dollars toward solving complex problems. But managing the open and competitive systems that allocate these resources is not without significant costs. Funders often receive far more applications than they can support—sometimes 5, 25, or even more than 100 proposals for every award they make. Most proposals are rejected, sometimes after long delays. Science funders, foundations, procurement offices, and even journal editors all face similar challenges: allocating scarce resources most effectively, while balancing time, cost, and high workloads on applicants.
At Stanford Impact Labs (SIL), we face this problem as well. We want to make rigorous, high-quality funding decisions in a timely manner so we can get out of the way and empower grantees to get straight to work.
To interrogate our own efficiency, we conducted a learning sprint to understand whether AI might be able to play a role. As we did, we surfaced an even larger question: Can AI meaningfully support the kind of complex, evidence-based analysis that funding decisions require?
In this post, we share how we evaluated AI in our review process and found that it can support decisions on par with those made by human reviewers, reducing costs by 10x, while providing us context-specific insights four months earlier in the process.
But more than these findings, we want to promote responsible AI use through a community that openly learns about what AI can and cannot do. While many organizations are exploring AI's role in research and the social sector, far fewer are openly evaluating these tools for high-stakes decisions such as allocating funds (a good example is MIT Solve). This is our attempt to contribute to this important conversation.
Our Review Process
Each year, SIL receives over 70 letters of interest (LOI) across two funding stages. Initially, generalist reviewers—academics, practitioners, and staff—evaluate the full pool against a shared rubric to shortlist roughly 15 proposals. We then invite subject matter experts into the process to provide deeper analytical review.
Though our generalist review process works, it carries inherent tradeoffs. Reviewers have limited time to dedicate to each proposal and often work outside their core expertise. Because rubric interpretation inevitably varies, the aggregating of diverse perspectives introduces noise. These are not flaws of the people involved; they are structural constraints in any broad first-round screening process.
We introduced a simple question here: could AI help improve consistency and efficiency in our shortlisting while preserving rigor and fairness? To answer this question, we set up a sprint to test whether AI could improve the consistency, depth, and efficiency of our first-round shortlisting process, and to share what we learned.
As part of our commitment to responsible AI, we conducted a detailed risk assessment and adopted a set of safeguards, including transparent communication and opt-out options for applicants; strong data security and privacy protections; clear accountability with human-in-the-loop review; and an explicit learning agenda.
The AI Solution
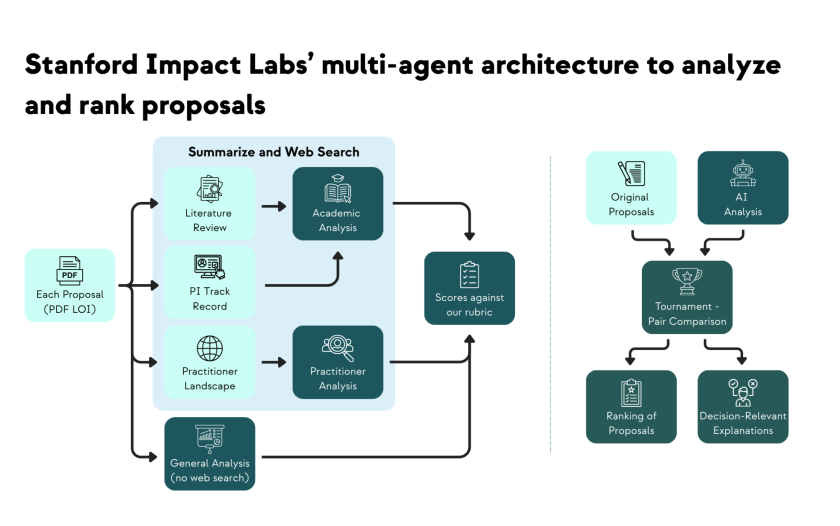
Recent advances in AI reasoning have made it possible to analyze research proposals relatively quickly and produce useful reports. But using chatbots systematically across dozens of LOIs has clear limitations: inconsistent depth, unfocused analysis, and outputs that do not support ranking decisions. Aware of needing something more structured, we built a multi-agent system for this task.
The specialized AI agents each handled distinct subtasks, mirroring the academic and practitioner perspectives central to our human review process, while augmenting our knowledge with detailed literature reviews and landscape analyses. But analyzing each individual proposal was not enough to generate decision-relevant insights based on our initial tests. So we reframed the problem: instead of asking "how good is this proposal?", we asked "which of these two proposals is stronger, and why?"
This led to a tournament where we staged over a thousand head-to-head matchups between proposals. For each match, a final AI agent compared two proposals and all their background AI analyses in order to decide which proposal to recommend and explain why. This tournament not only produced an ordered ranking of proposals1, it also generated narratives explaining why a proposal was stronger or weaker than others in the same pool. This was not just automation, it augmented our process to do things that previously were not possible: full rankings with structured comparative reasoning about every proposal in our application pool.
What We Learned
Beyond building the tool, our goal throughout this test was to understand whether AI could support quality funding decisions. Even though there is no objective benchmark for what the "right" shortlist looks like, we still needed a benchmark in order to evaluate this solution. First, we designed a backtest using four years of investment data, where we measured how well generalist reviewer rankings aligned with our actual funding decisions. With this, we then asked whether AI rankings could match that baseline. Next, we chose to develop the tool in parallel with conducting our 2025-2026 funding cycle. This allowed us to compare our business-as-usual choices to the AI output and rankings. This is what we found:
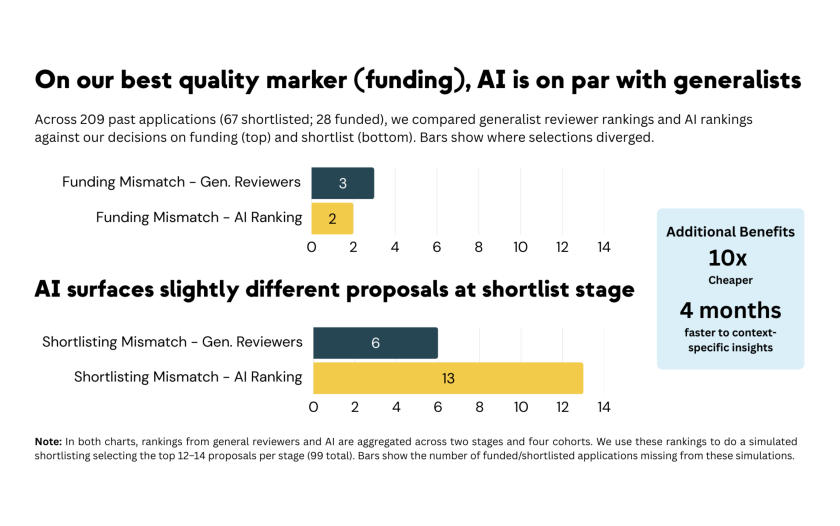
AI can aid our shortlisting decisions at 10x lower cost and significantly less time. The AI system produced rankings and detailed reports for our entire pool in two days at a cost of roughly $200, compared to approximately $3,000 for our standard process. We got the type of context-specific insights we typically only get from subject-matter experts 4 months faster than we would have otherwise. These efficiency gains make rethinking our shortlisting process possible.
AI was on par with generalist reviewers at identifying funded proposals. In our backtest across more than 200 applications, AI matched generalist reviewers at spotting the proposals we ultimately funded, our best signal for quality decision-making. AI recommended slightly different projects for shortlisting, but given it performs well at spotting the funded projects, these AI shortlisting mismatches are not necessarily concerning. Given we have limited information and capacity in our early-stage screening, it is possible AI could spot something we missed.
Having additional AI-supported research demonstrated value beyond rankings. In our current funding cycle, we ran a parallel test: running our cycle as we normally do and then revealing carefully designed AI reports to key decision makers before the final shortlisting concluded. This design allowed us to assess whether AI added information that wasn’t otherwise available. We saw how the AI output aligned with many of our assessments and how it informed decisions on marginal proposals, surfacing considerations that human reviewers had not flagged. The AI-generated reports also proved useful later in the process. They helped us identify better subject matter experts for our second round of reviews and helped us think through key questions for applicant interviews. Both of these outcomes improved our process in ways we had not anticipated.
AI has real limitations, requires humans-in-the-loop, and its risks need further study. We learned that AI could potentially change some of our shortlisting decisions. Although initial analysis suggests this might affect more certain fields or methods, distinguishing potential bias from improved decision-making is very complex. We have more work to do on this and expect to continue sharing what we find. Clear accountability for decision-making and human review of all proposals will not be going away at SIL.
The Road Ahead
This AI learning sprint reshaped how we think about AI's role in funding. Our goal was never to replace human reviewers, but to redesign how and where the scarce resource of human attention can be better spent. This includes exploring how AI-generated analyses can help staff and reviewers focus on the marginal proposals, where deeper deliberation matters most. This also means continuing to uphold our commitment to responsible AI, constantly iterating and evaluating how we use and think about these tools.
As we continue to test and improve our tool, we plan to share our system publicly while learning from others along the way. We recognize that Stanford Impact Labs is one of many funders engaging the core question we started with: Can AI meaningfully support the kind of complex, evidence-based analysis that funding decisions require? As such, we believe that openly sharing about where AI advances our work and where it may fall short, matters more than the evolution of any particular tool.
If you are a funder or researcher interested in this work, we would be excited to hear from you. Sign up here to get updates on our github repo and the full report of this evaluation.
1 To rank proposals we actually used an Elo rating algorithm, famous for its use to rank chess players. Versions of this algorithm are used by others working on AI solutions when ranking AI output on complex measures of quality (e.g. AI as a Co-Scientist, Autonomous Policy Evaluation)